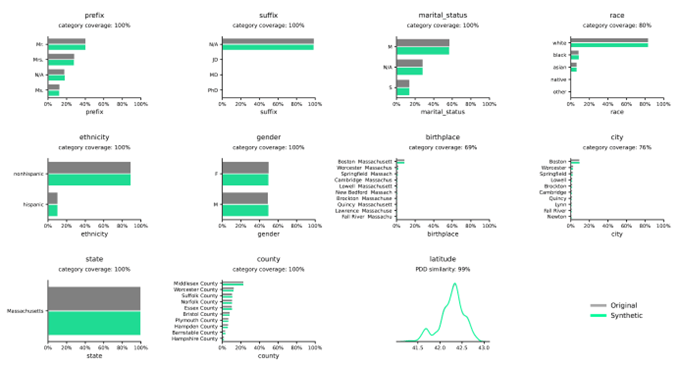
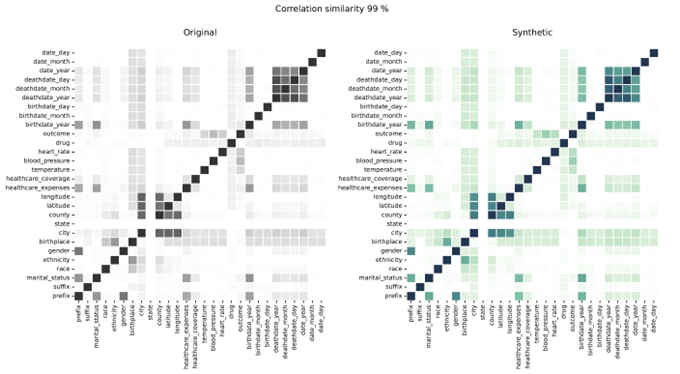
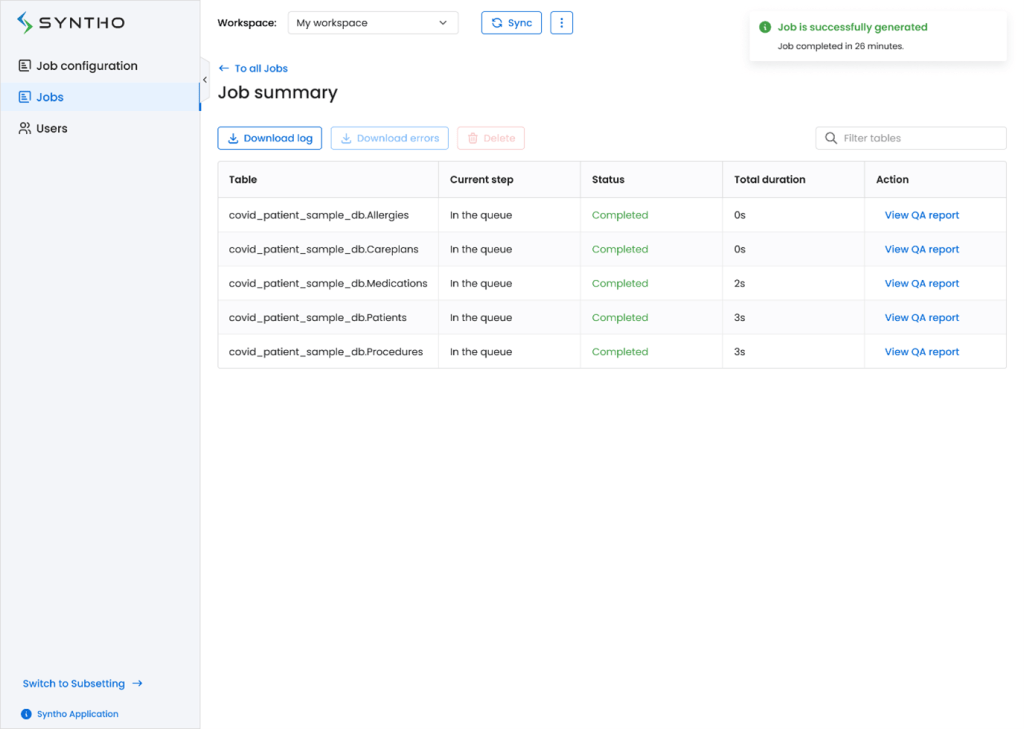
Data utility refers to how well a dataset meets the needs of its intended use. It encompasses accuracy, completeness, consistency, reliability, and relevance. High-quality data is accurate and free from errors, inconsistencies, or duplications, ensuring it can be effectively used for analysis, decision-making, and operational purposes.