



Syntho imite les données (sensibles) avec l'IA pour générer des jumeaux de données synthétiques
Syntho utilise l'intelligence artificielle (IA) avancée pour créer des données synthétiques qui imitent avec précision les données sensibles. Notre objectif est de générer des données synthétiques de la plus haute précision, par rapport aux données d'origine. En utilisant notre Logiciel Syntho Engine et des modèles d'apprentissage automatique de pointe, nous pouvons générer des points de données entièrement nouveaux tout en conservant les mêmes modèles et relations statistiques trouvés dans les données d'origine. Le résultat est des données synthétiques qui préservent les caractéristiques clés des données d'origine, les rendant impossibles à distinguer des données réelles, de sorte qu'elles peuvent même être utilisées à des fins d'analyse. Par conséquent, nous appelons ces données synthétiques générées par l'IA un jumeau de données synthétiques, parce qu'il est "aussi bon que réel par rapport aux données réelles. En tirant parti des jumeaux de données synthétiques, les entreprises peuvent débloquer de nombreux avantages via diverses données synthétiques à valeur ajoutée cas d'utilisation.
Question clé : quelle est la précision des données synthétiques par rapport aux données réelles ?
Partie 1
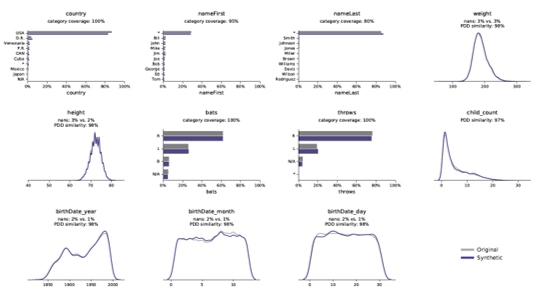
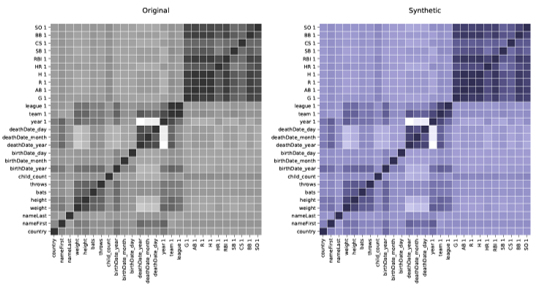
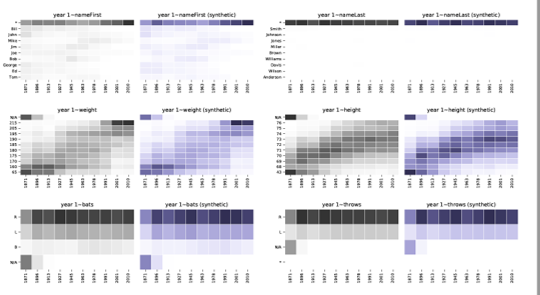
Chez Syntho, nous comprenons l'importance de données fiables et précises pour votre entreprise. C'est pourquoi nous fournissons un rapport d'assurance qualité complet pour chaque analyse de données synthétiques, qui démontre l'exactitude des données synthétiques par rapport aux données originales. Notre rapport de qualité comprend diverses mesures telles que les distributions, les corrélations, les distributions multivariées, les mesures de confidentialité, etc. De cette façon, vous pouvez facilement évaluer que les données synthétiques que nous fournissons sont de la plus haute qualité et peuvent être utilisées avec le même niveau de précision et de fiabilité que vos données d'origine.
Partie 2
Bien que Syntho soit fier d'offrir à ses utilisateurs un rapport d'assurance qualité avancé, qui est généré automatiquement par notre moteur Syntho, nous comprenons également l'importance d'avoir un évaluation externe et objective de nos données synthétiques. C'est pourquoi nous avons demandé l'aide de SAS, un expert des données de premier plan, pour évaluer nos données synthétiques.
SAS effectue diverses évaluations approfondies sur l'exactitude des données, la protection de la vie privée et la facilité d'utilisation des données synthétiques générées par l'IA de Syntho par rapport aux données d'origine. En conclusion, SAS évalué et approuvé les données synthétiques de Syntho comme étant exactes, sécurisées et utilisables par rapport aux données d'origine.
Instantanés de notre rapport synthétique sur la qualité des données
Références externes
Pour l'étude de cas, l'ensemble de données cible était une entreprise de télécommunications base de données. L'ensemble de données contient 128 colonnes, dont une colonne indiquant si un client a quitté l'entreprise (c'est-à-dire 'churned') ou non. L'objectif de l'étude de cas était d'utiliser les données synthétiques pour entraîner certains modèles afin de prédire l'attrition des clients et d'évaluer les performances de chaque modèle. Étant donné que la prédiction du taux de désabonnement est une tâche de classification, SAS a sélectionné cinq modèles de classification populaires pour effectuer les prédictions, notamment :
Avant de générer les données synthétiques, SAS a divisé de manière aléatoire l'ensemble de données de télécommunications en un ensemble de trains (pour entraîner les modèles) et un ensemble d'attente (pour évaluer les modèles). Le fait de disposer d'un ensemble d'exclusions distinct pour la notation permet une évaluation impartiale de l'efficacité du modèle de classification lorsqu'il est appliqué à de nouvelles données.
En utilisant le train comme entrée, Syntho a utilisé son moteur Syntho pour générer un ensemble de données synthétiques. Pour le benchmarking, SAS a également créé une version anonymisée de la rame après avoir appliqué diverses techniques d'anonymisation pour atteindre un certain seuil (de k-anonymat). Les étapes précédentes ont abouti à quatre ensembles de données :
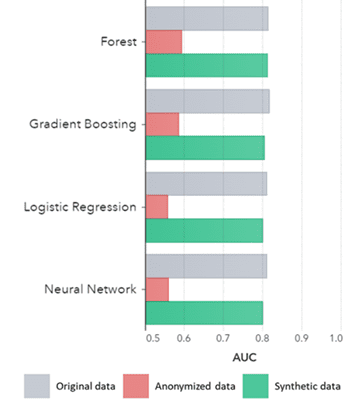
Les ensembles de données 1, 3 et 4 ont été utilisés pour former chaque modèle de classification, ce qui a donné 12 (3 x 4) modèles formés. SAS a ensuite utilisé l'ensemble de données d'exclusion pour mesurer la précision avec laquelle chaque modèle prédit l'attrition des clients. Les résultats sont présentés ci-dessous, en commençant par quelques statistiques de base.
Données synthétiques non seulement pour les modèles de base (comme indiqué dans les anciens tracés du rapport Syntho QA), il capture également les modèles statistiques «cachés» profonds requis pour les tâches d'analyse avancées. Ce dernier est démontré dans le graphique à barres, indiquant que la précision des modèles formés sur des données synthétiques par rapport aux modèles formés sur des données originales est à égalité. De plus, avec un aire sous la courbe (AUC*) proche de 0.5, les modèles entraînés sur des données anonymisées sont de loin les moins performants. Le rapport complet avec toutes les évaluations analytiques avancées sur les données synthétiques par rapport aux données originales est disponible sur demande.
De plus, ces données synthétiques peuvent être utilisées pour comprendre les caractéristiques des données et les principales variables nécessaires à la formation réelle des modèles. Les entrées sélectionnées par les algorithmes sur les données synthétiques par rapport aux données originales étaient très similaires. Par conséquent, le processus de modélisation peut être effectué sur cette version synthétique, ce qui réduit le risque de violation de données.
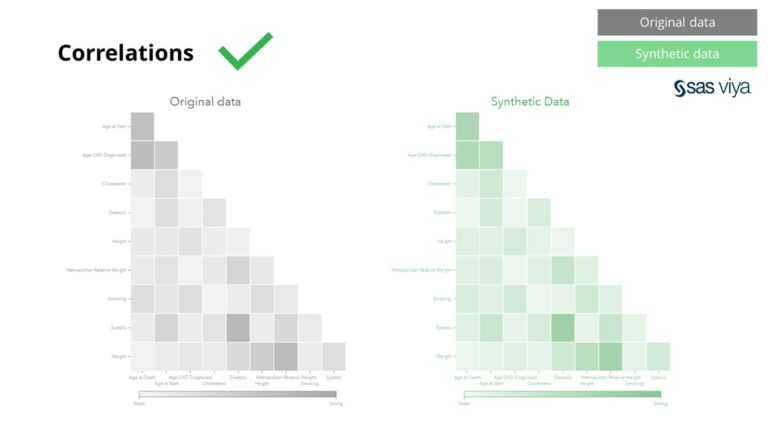
Les corrélations et les relations entre les variables ont été préservées avec précision dans les données synthétiques.
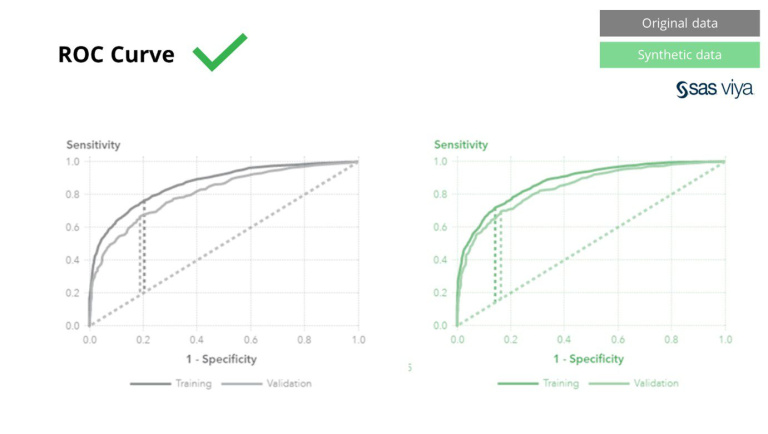
L'aire sous la courbe (AUC), une mesure de mesure des performances du modèle, est restée constante.
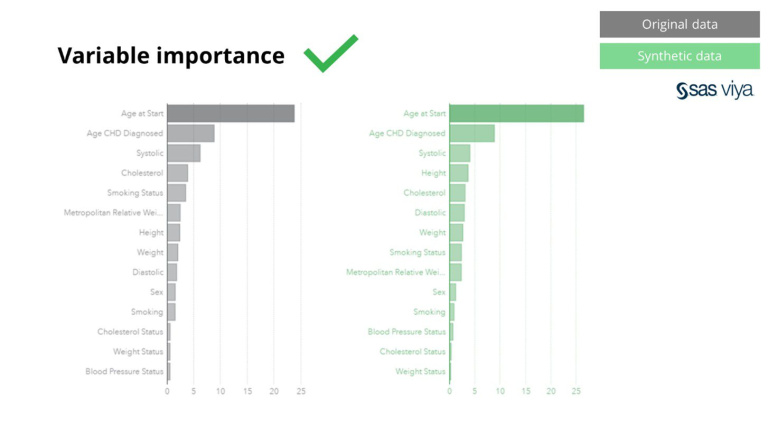
De plus, l'importance de la variable, qui indiquait le pouvoir prédictif des variables dans un modèle, est restée intacte lors de la comparaison des données synthétiques à l'ensemble de données d'origine.
Sur la base de ces observations, nous pouvons conclure avec confiance que les données synthétiques générées par le Syntho Engine dans SAS Viya sont en effet à égalité avec les données réelles en termes de qualité. Cela valide l'utilisation de données synthétiques pour le développement de modèles, ouvrant la voie à la recherche sur le cancer axée sur la prédiction de la détérioration et de la mortalité.
